

 Télécharger l'article
Télécharger l'article

Introduction
Les contenus produits par les organisations s’inscrivent dans des mécanismes d’éditorialisation définis comme des « processus traversant l’ensemble des activités liées à la publication de contenus sur le web » (Broudoux, 2022) qui peuvent différer selon l’intentionnalité qu’ils portent. Ainsi, nous distinguons, les contenus opérationnels et contenus stratégiques, souvent à visée info-performative (Lefebvre-Reghay, 2024), des contenus journalistiques et scientifiques. En effet, ils se distinguent par leur capacité à s’adapter aux contraintes du référencement et à exister indépendamment de leur contexte d’origine. Parmi les contenus stratégiques, nos travaux se sont intéressés à une catégorie de contenus textuels que nous appelons « écritexte ». Ce type de texte est produit en contexte organisationnel. Nous le définissons comme un contenu numérique complexe, alliant la matérialité de l' « écrit » — objet concret lié à la traçabilité et aux pratiques performatives (Fraenkel, 2006) — et l'intangibilité du texte, entendu comme un ensemble de signes véhiculant des significations indépendamment de sa forme matérielle. Le terme « écritexte » permet, à notre sens, de combler un vide conceptuel et mieux désigner une catégorie particulière de contenus numériques se situant à l'intersection de l'écrit et du texte. Ce néologisme souligne les spécificités de cet objet hybride et polysémique qui se distingue par sa capacité à exister indépendamment de son contexte d'origine et à répondre aux exigences des dispositifs numériques, incluant l'optimisation pour le référencement (SEO) (Huot, 2023) et l'intégration d'éléments techniques comme le balisage HTML propres aux écrits d’écran (Souchier, 1996) ou ses marqueurs « textiels » (Mayeur, Desprès-Lonnet 2020). Leur nature info-performative (Lefebvre-Reghay, 2024) les positionne enfin comme des vecteurs essentiels dans l'économie de l'attention (Simon, 1969), visant à capter, convertir et fidéliser les audiences dans un environnement de surabondance informationnelle.
L’exemple incarnant ce concept d’écritexte, notion qui permet de dépasser les catégories traditionnelles de l’écrit professionnel, est ce que les professionnels de la communication numérique et les référenceurs web appellent : le netlinking, terme désignant à la fois la technique de référencement « naturel » et le texte incarnant l’intentionnalité de celle-ci. Ce format d’« écriture efficace » (De Angelis, 2024) revêt la forme d’un article de presse, tout en intégrant trois liens (un vers la page du donneur d’ordre, un vers un site évoquant le sujet, un vers un site d’autorité de type Légifrance). Sa publication monnayée fait du netlinking un publi-rédactionnel classique importé du monde de l’imprimé en contexte numérique, un publi-rédactionnel à visée performative. Ce format d’écriture stratégique est largement utilisé dans le référencement naturel (SEO), car il combine des éléments textuels normés (titre, chapô, intertitres, paragraphes courts) et des hyperliens stratégiquement intégrés. Hybride par nature, il allie la performativité du texte (capacité à capter l’attention et à générer du trafic) à la matérialité d’un écrit mesurable et traçable dans des indicateurs de performance numérique (taux de clic, SEO). En ce sens, un netlinking incarne pleinement la dualité d’un écritexte et illustre les tensions entre les exigences techniques et stratégiques qui caractérisent ces contenus.
Dans ce contexte, les technologies numériques, et en particulier l’intelligence artificielle (IA) — définie par sa capacité à exécuter des fonctions intellectuelles humaines, telles que le raisonnement et l’apprentissage, selon la norme ISO/IEC 2382 -28 — transforment les pratiques éditoriales et bouleversent les paradigmes théoriques par ses questionnements non résolus (Kuhn, 1962) quant à l’autorialité — reconnaissance juridique de la paternité d’un contenu — et l’auctorialité qui concerne l’autorité créative conférée à l’auteur sur l’œuvre elle-même (Foucault, 1969 ; Genette, 1987). Ces distinctions sont essentielles pour comprendre ce que nous appelons la « trivialisation épistémologique de l’écrit professionnel », phénomène par lequel cet objet est réduit à un ensemble de supports purement pratiques et utilitaires, excluant tout intellectualité puisqu’il est considéré que leur valeur réside uniquement dans leur capacité à exécuter une tâche ou à transmettre une information sans considération de la réflexion, de la créativité ou de l’effort intellectuel qu’ils requièrent. C’est sans doute ce qui fait de sa perception comme « un objet difficile à cerner » (Labasse, 2009) et par sa protection juridique insuffisante dans le cadre des lois de la propriété intellectuelle, lesquelles ne clarifient pas le statut d'« œuvre de l'esprit » (Gervais, 1998), sauf par jurisprudence pour des cas spécifiques tels que les slogans publicitaires (Chatry, 2016).
Il en découle une marginalisation des rédacteurs web, souvent invisibilisés par les organisations (Krinsky, Simonet, 2012) qui s’approprient leurs contributions. Cette invisibilisation systémique, visant à effacer toute reconnaissance des rédacteurs en tant qu'auteurs, accentue la dévalorisation de leurs compétences à créer des contenus authentiques et de qualité. En effet, puisqu’ils ne sont pas reconnus, leur rôle peut être perçu comme secondaire et facilement automatisable. Le corollaire de l’automatisation croissante est la réduction de leur rôle dans la création de valeur. À terme, cette dynamique fragilise toujours plus la reconnaissance de leur apport dans les processus éditoriaux avec pour corollaire la précarisation de ce métier jugé interchangeable et inutile. De plus, l'anonymisation des contenus rend plus difficile leur traçabilité en raison de la perte de paternité des contenus, ou d’une attribution floue, ce qui peut impacter la qualité des productions. Face à ces défis, peut-on penser une éthique rédactionnelle pour redonner leur place aux rédacteurs web ? Et, l'IA peut-elle être mobilisée pour renforcer leur visibilité et leur rôle dans la chaîne éditoriale ?
Cet article propose d’explorer la déontologie des rédacteurs web (Beaudet, Rey, 2014) pour poser les jalons de l’éthique rédactionnelle au prisme du concept d’écritextes, qui vise à en enrichir la compréhension. Notre approche intègre les dimensions matérielles et immatérielles des écritextes pour discuter du rôle de l’IA dans la reconnaissance de l’identité numérique des rédacteurs à travers le processus de tokenisation. Ainsi, contrairement aux approches abordant séparément les enjeux déontologiques et technologiques, cette étude explore leur convergence, en montrant comment la tokenisation, adossée à l’IA, peut non seulement renforcer la transparence et l’authenticité des écritextes, et plus largement des contenus numériques, mais aussi redéfinir les pratiques rédactionnelles par l’attribution et la protection des droits d’auteur, sans sacrifier les droits des organisations dans le cadre de co-autorialité ; l’objectif étant de répondre aux défis éthiques imposés par la constante mutation de l’environnement numérique (Doueihi, 2008).
La nécessaire émergence d’une éthique rédactionnelle
L’exploration de la dynamique de la production de contenu numérique amenant à la définition des écritextes nous a naturellement amenée à nous intéresser à leurs créateurs et à leur ressenti quant à la reconnaissance de leur travail. Nous avons donc réalisé un questionnaire diffusé sur LinkedIn entre mars et août 2023 auprès des rédacteurs web et présenté lors des Doctorales de la SFSIC (Lefebvre-Reghay, 2024). Ses résultats indiquent que cette profession est relativement équilibrée au prisme du genre, avec une légère majorité féminine (55 %). La tranche d’âge prépondérante oscille entre 25 et 35 ans et la majorité des rédacteurs web sont hautement qualifiés : 52 % des femmes et 56 % des hommes ont un niveau d'études Bac+5 ou plus. La précarité est toutefois un aspect marquant de leur activité : environ 32 % des rédacteurs cumulent leur métier avec d'autres activités. De plus, une part significative exerce sous le statut de micro-entrepreneur, privilégiant la flexibilité, bien que les hommes aient davantage accès à des emplois stables en CDI ou CDD. L’enquête a également mis en exergue un besoin croissant de reconnaissance, notamment à travers le droit à la signature, perçu par 75 % des répondants comme un levier essentiel de visibilisation, examinée au prisme des concepts d’identité numérique (Cardon, 2021) ou identicité et d’autorialité, piliers de l’éthique rédactionnelle nécessaire à la résolution partielle du paradoxe de la transparence. À notre sens, l’identicité englobe la manière dont ils se présentent en ligne, les traces qu’ils laissent à travers leurs écrits, enfin l’impact de leurs contenus sur la perception qu’ont les autres de leur expertise et de leur crédibilité. Quant à l’autorialité, elle suppose la reconnaissance de leur contribution substantielle à la création de contenus de valeur, aujourd’hui éclipsée par la marque ou l’organisation pour laquelle ils écrivent.
Ainsi, au regard des résultats de l’enquête et de notre propre travail de terrain, nous constatons que leur visibilité est souvent éclipsée par les organisations pour lesquelles ils créent du contenu, ce qui peut nuire à la reconnaissance de leurs compétences et, par extension, à la qualité des contenus diffusés. Il est donc crucial de redéfinir l’identité numérique des rédacteurs en rétablissant le lien entre leur expertise et l’impact de leurs contributions afin de renforcer l’éthique rédactionnelle.
L’exigence de transparence en contexte numérique
Depuis 2017 et le Brexit, les « fake news » (Badouard, 2020) sont devenues un sujet de préoccupation très important avec en filigrane la déstabilisation d’un modèle : notre démocratie. Par ailleurs, fin 2023, sur fond de révélations relatives au fonctionnement du moteur de recherche lors de son procès antitrust, Google dévoilait de nouveaux algorithmes, dont Helpful Content Update, qui vise à répondre aux besoins des « people-first » en mettant en avant les contributions originales des auteurs dans un souci de transparence et de qualité ; les contenus non utiles pouvant potentiellement déclasser le site qui les publie.
Cette avancée salutaire pour la sphère numérique mondiale a cependant été remise en question en 2023 par une innovation disruptive : le modèle GPT (Generative Pre-trained Transformer) d’Open AI. Capable de générer du contenu textuel original (Lamri, J., Tertrais, G. et Silver, A., 2023), ce modèle a également présenté en juillet 2024 puis propulsé en novembre de la même année, SearchGPT, un outil d’IA qui se distingue par sa capacité à fournir des réponses contextuelles et conversationnelles intégrant des sources, comme des articles de presse, avec pour corollaire une interaction utilisateur redéfinie. L’hégémonie de Google dans le domaine de la recherche en ligne et des systèmes de recommandation, est ainsi questionnée par l’intelligence artificielle, nous imposant de repenser l’interaction avec l’information. Open AI, avec SearchGPT, situé à mi-chemin entre un moteur de recherche classique et un modèle conversationnel, introduit une concurrence inédite pour Google, qui avait déjà été contraint à lancer fin 2023 « Gemini » intégré au système SGE afin de limiter les impacts de l’arrivée du modèle GPT.
Ces outils basés désormais sur l’intelligence artificielle se positionnent comme les leviers clés dans l’accès à l’information, notamment grâce à leur capacité à améliorer les systèmes de recommandation, comme souligné par Kantor et Ricci (2011). Toutefois, comme l’a conceptualisé le blogueur canadien Cory Doctorow avec le terme d’« enshittification » ou « merdification » du Web, ces avancées posent également des défis, notamment en matière de qualité et de gestion de vastes volumes de données générées quotidiennement sur Internet (Manning et al., 2008). En réponse, Google et OpenAI mettent en avant leurs efforts pour améliorer la qualité de l’information en ligne, notamment avec des initiatives comme la mise à jour « Helpful Content Update » en 2022 ou les fonctionnalités avancées de SearchGPT.
Selon Maingueneau (2012) et Paveau (2017), chaque discours est encadré par un système de « règles invisibles » qui en détermine les contours acceptables. Comme évoqué précédemment, l’IA joue désormais un rôle crucial dans la génération de contenus textuels. Cependant, son influence ne se limite pas à la production automatisée : elle redéfinit également les règles discursives qui encadrent la rédaction web. Ces règles intègrent à la fois les principes traditionnels du SEO - recherche et sélection de mots-clés, structure de contenu, qualité et pertinence du contenu, optimisation des balises méta, maillages interne et externe, optimisation des images, temps de chargement des pages et expérience utilisateur selon Canivet (2021) -, mais aussi les directives dictées par les capacités et les limites des outils IA comme SGE. Par exemple, des algorithmes comme E-E-A-T (Expertise, Experience, Authoritativeness, Trustworthiness), développé par Google, redéfinissent les attentes des moteurs de recherche; ces derniers valorisant des contenus de haute qualité répondant à des critères spécifiques comme l’expertise, l’autorité et la fiabilité des auteurs, mais aussi l’expérience offerte par le contenu. Toutes ces injonctions façonnent la manière dont les contenus doivent être structurés, non seulement pour plaire aux algorithmes de recherche, mais aussi pour engager de manière efficace les utilisateurs humains. Nous sommes donc face à un conflit de normes (Devriendt, 2017) qui se traduit, entre autres, par des tensions entre les exigences de rapidité et d’automatisation imposées par les outils IA et la nécessité de produire des contenus éthiques et traçables. Cela soulève des questions complexes relatives à l’interaction entre la qualité attendue par Google, l’optimisation des moteurs de recherche (SEO) au prisme de l’IA, enfin l’éthique relative à l’autorialité des contenus (Broudoux, 2022) proposés aux internautes.
La Commission européenne a réagi en créant un « Code renforcé de bonnes pratiques contre la désinformation », adopté par 34 signataires, dont la France. Ce Code vise à renforcer les mesures contre la désinformation en ligne, tout en respectant les droits fondamentaux des citoyens, notamment grâce à la coopération étroite entre les différents acteurs de l’écosystème numérique : plateformes, annonceurs, chercheurs, vérificateurs de faits. Il prévoit des outils de transparence et de surveillance, particulièrement de l’intelligence artificielle en raison de sa capacité à générer et manipuler du contenu. Il oblige ainsi à la mise en place urgente de règles strictes sur la qualité des données et la traçabilité des contenus. L’Artificial Intelligence Act, adopté en décembre 2023 et devant entré en vigueur dès 2025, complète ce Code par les règles qu’il instaure en matière de qualité des données utilisées pour entraîner les algorithmes. Si les développeurs de systèmes d’IA sont tenus à des obligations de transparence, telles que l’identification explicite des contenus artificiels (sons, images et textes) produits, celles-ci restent générales et n’intègrent pas de mesures contraignantes spécifiques au respect des droits d’auteur. À ce jour, cette question demeure en débat, les ayants droit se mobilisant pour qu’elle soit intégrée dans les futures étapes de mise en œuvre ou dans de nouvelles réglementations complémentaires.
Toutefois, ces efforts de régulation restent essentiellement réactifs et peinent à anticiper les évolutions rapides de la technologie. L’émergence d’algorithmes tels que le modèle GPT, capables de manipuler les contenus de manière autonome, illustre parfaitement ces limites. Cela est d’autant plus vrai que des tensions persistent entre la nécessité de rendre les informations accessibles et les contraintes imposées par les acteurs du numérique. Les écritextes, en tant qu'objets hybrides inscrits dans un contexte numérique complexe, reflètent ces tensions. Ils exigent une réflexion approfondie sur les normes rédactionnelles et la manière dont l'autorialité peut être valorisée, en particulier notamment dans les environnements où les contributions humaines risquent d’être éclipsées par les outils IA.
La question de leur traçabilité implique une certaine transparence considérée comme une illusion en sciences de l’information et de la communication, toute situation communicationnelle étant médiée et façonnée par des dispositifs techniques, culturels et sociaux (Jeanneret, 2001). De plus, les écritextes sont plus que jamais intrinsèquement liée aux infrastructures technologiques qui les sous-tendent. Et, ces dernières, loin d’être neutres, participent à façonner la manière dont les informations sont produites, diffusées et perçues, créant des biais structurels (Chartron, 2022). De fait, si les nouvelles réglementations mettent l’accent sur la qualité des données et la traçabilité des contenus, elles ne suffisent pas à garantir une transparence. Les écritextes, définis comme des contenus numériques alliant matérialité et intangibilité, soulèvent donc des enjeux spécifiques en matière d’éthique et d’autorialité.
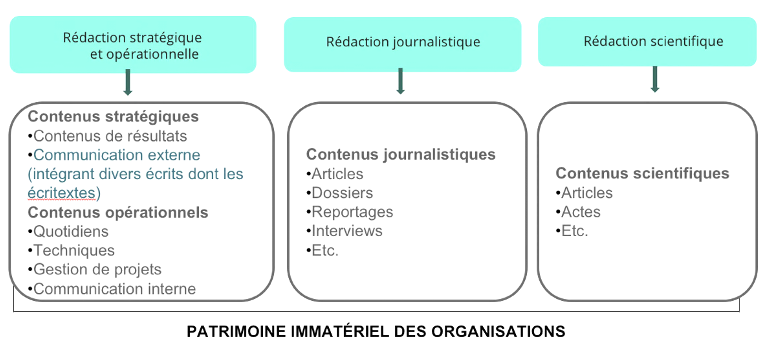
Dans ce contexte, nous pensons qu’il est toutefois possible de promouvoir une culture de l’éthique rédactionnelle en plaçant les rédacteurs web au centre des pratiques éditoriales par la reconnaissance de leur autorialité. Concrètement, cela signifierait la mise en place de dispositifs visant à attribuer clairement la paternité des contenus produits, tels que la signature systématique des textes par les rédacteurs, y compris dans la cadre d’une co-rédaction stratégique et opérationnelle avec les organisations privées (toutes les entreprises non journalistiques), publiques (hors communautés de chercheurs) ou relevant de l’économie sociale et solidaire ; l’intégration de métadonnées précisant l’auteur ou bien encore la tokenisation des écritextes que nous aborderons ultérieurement afin d’en garantir l’authenticité et l’intégrité. Ces dispositifs contribueraient à une plus grande transparence, entendue ici comme la visibilité et l’accessibilité des informations pertinentes à tous, sans dissimulation. Ils renforceraient la confiance, la responsabilité et la vérifiabilité des informations diffusées par les parties prenantes à la création des écritextes dont les enjeux d’autorialité sont à envisager au prisme de la distinction entre les différents types de rédaction représentés ci-dessous. Toutefois, cette transparence, dans sa dimension opérationnelle, reste insuffisante si elle n’est pas accompagnée d’une réflexion plus large sur les normes éthiques et les dynamiques relationnelles qui structurent la production et la diffusion des contenus numériques.
Représentation de la rédaction professionnelle
Le paradoxe de la transparence
Dans l’article « La transparence : l’utopie du numérique ? », Sidonie Gallot et Lise Verlaet (2016) explorent le paroxysme de la transparence, décrite comme une injonction de participation à la société de l’information, qui formerait aujourd’hui l’utopie d’un numérique scénarisé, exacerbant la métaphore théâtrale développée par Goffman (1973). En effet, l’institutionnalisation de la transparence et son ancrage dans l’imaginaire collectif mettent en exergue le paradoxe d’une société hypercommunicante qui reste cloisonnée par la technique. Cependant, la notion d’enfermement algorithmique est discuté : l’idée que les contenus que nous recevons sont filtrés par des algorithmes en fonction de nos comportements et préférences en ligne, popularisée par le militant Eli Pariser (2012) sous le concept de « bulles de filtre », se présente plutôt comme une dynamique instable qui n’est pas propre au numérique (Citton, Lechner, & Masure, 2023). Il n’en demeure pas moins que le concept n’est pas non plus entièrement réfuté.
Au-delà de ce possible enfermement algorithmique, l’utopie numérique est donc double : elle inclut à la fois la transparence technique du support numérique et une transparence active des acteurs impliqués dans une volonté politique d’engagement et de publicité. Le cas des rédacteurs web, travailleurs invisibilisés (Krinsky, Simonet, 2012) est intéressant pour appuyer cette idée. En effet, ils sont les héritiers d’un modèle imprimé où les organisations privées et publiques, en matière de paternité des contenus stratégiques et opérationnels, effacent leur identité.
Cette invisibilisation systématique, bien que différente de l’effacement symbolique de l’auteur littéraire théorisé par Barthes (1967), trouve une résonance dans le contexte numérique. Cette invisibilisation systématique en contexte organisationnel trouve une résonance dans l’effacement symbolique de l’auteur littéraire théorisé par Barthes (1967), qui vise à libérer le texte de toute autorité et à permettre aux lecteurs de construire leurs propres significations. Cependant, l'effacement des rédacteurs web est d’une nature différente : il est davantage institutionnel et pragmatique, car il ne libère pas le texte, mais le recentre autour des intérêts commerciaux et stratégiques de l’organisation, qui s’approprie l’autorialité et le droit moral des contenus produits. Cela pose des questions complexes sur la manière dont les principes de transparence peuvent être appliqués dans un contexte où les intérêts commerciaux et la protection des droits d’auteur sont en jeu, tout en assurant la reconnaissance des rédacteurs en tant que contributeurs essentiels.
En dehors des débats politiques sur la transparence, on peut donc voir s’affronter d’un côté la transparence qui vise à garantir la confiance et la crédibilité des contenus en ligne ; de l’autre, l’exposition des rédacteurs web et des organisations à des tensions entre la divulgation complète et la protection de leurs intérêts. In fine, ces tensions peuvent contrarier les objectifs des organisations, mais aussi remettre en question la reconnaissance des compétences et les valeurs des rédacteurs web, dont l’identité est souvent dissoute dans celle des organisations. On peut donc légitimement se demander dans quelle mesure leur invisibilisation favorise la désinformation, l’infobésité, et la mauvaise qualité des contenus publiés.
Là encore, les limites des approches réglementaires actuelles s’imposent à l’esprit. Car, malgré les efforts législatifs récents pour encadrer la qualité des données et la traçabilité des contenus, ces mesures s’avèrent insuffisantes pour garantir une transparence numérique véritablement efficace d’autant plus que la notion même de transparence est souvent perçue comme une notion relative. Les réglementations existantes, bien qu’essentielles, se concentrent principalement sur le respect des droits d’auteur pour une certaine catégorie de contenus et la classification de ces derniers. Mais elles n’adressent pas pleinement des problématiques plus complexes et systémiques comme les bulles de filtre, l’infobésité, et l’opacité des algorithmes. Pour dépasser ces limites, nous proposons le cadre conceptuel de la transparence. Plutôt que de la considérer comme un objectif absolu, elle doit être envisagée comme un principe relationnel, impliquant à la fois une traçabilité accrue des contenus numériques et une reconnaissance des contributeurs à travers une « éthique rédactionnelle ». Ce cadre complémentaire, fondé sur des principes tels que l’autorialité et la co-création, offre une voie pour pallier les insuffisances des régulations actuelles tout en protégeant et valorisant les rédacteurs web.
L’éthique rédactionnelle pour plus de transparence ?
Pour résoudre partiellement ce paradoxe, nous proposons de développer la notion d’éthique rédactionnelle. Qu’entendons-nous par là ? Selon nous, l’éthique rédactionnelle se réfère aux principes moraux et aux standards professionnels que les rédacteurs suivent dans leur travail, mais aussi à la nécessaire responsabilité sociale des entreprises que celles-ci se doivent de déployer pour favoriser la transparence numérique. De part et d’autre, cela exige donc quatre prérequis : l’exactitude, la sincérité, l’équité, la confidentialité. L’éthique rédactionnelle repose ainsi, selon nous, sur deux paradigmes principaux.
a) Les compétences et les valeurs des rédacteurs
Parmi les compétences fondamentales du rédacteur, nous reprenons à notre compte toutes les compétences citées lors de l’enquête menée par Beaudet et Rey :
« Écouter attentivement, écrire avec clarté et exercer un bon jugement sont trois réponses qui font consensus parmi les répondants. Vient ensuite la compétence de comprendre l’objectif communicationnel du client et de respecter les lecteurs. En ce qui a trait aux besoins du client, tous ont spécifié devoir aider ce dernier à définir ses besoins et à éclairer sa démarche de communication (buts rhétoriques et pragmatiques). En d’autres termes, les répondants ont tous mis en évidence que souvent le client ne savait pas comment atteindre ses objectifs de communication et que le rédacteur était responsable de lui proposer la meilleure solution dans les circonstances. »
À cela s’ajoutent d’autres caractéristiques : « l’atteinte des objectifs du client, la conformité de l’écrit avec les exigences du mandat, la facilité de lecture et la qualité de la langue » (ibid). Une langue de qualité est décrite comme étant limpide, comprise par le plus grand nombre, avec un style simple et respectant la grammaire et la syntaxe. « Ces réponses sont cohérentes avec l’importance qu’accordent les répondants à la responsabilité du contenu de leurs écrits » (ibid). Or, à notre sens, endosser cette responsabilité exige en premier lieu de reconnaître le droit moral des rédacteurs web sur la création des contenus organisationnels, ce qui actuellement n’est pas le cas dans la mesure où il y a un impensé dans le Code de la Propriété intellectuelle quant à la définition d’auteur.
« L’auteur d’une œuvre de l’esprit jouit sur cette œuvre, du seul fait de sa création, d’un droit de propriété incorporelle exclusif et opposable à tous.
Ce droit comporte des attributs d’ordre intellectuel et moral ainsi que des attributs d’ordre patrimonial, qui sont déterminés par les livres Ier et III du présent code. »
Cela s’explique principalement par « la porosité des concepts et des pratiques professionnelles » (ibid) mise en exergue par les travaux de Fonvielle & al. (2012) relatifs à l’évolution lexicographique des termes auteur, rédacteur, écrire, rédiger à travers l’histoire et amenant Beaudet et Rey à définir le rédacteur comme :
« communicateur au sens où son engagement est à la fois personnel et public. Sur le plan personnel, le rédacteur engage ses compétences langagières et communicationnelles, s’investit comme sujet à part entière dans une action qu’il contribue à façonner. Sur le plan professionnel, il se met au service d’un mandant, donne forme à un message porteur d’intention à l’égard de la communauté et travaille dans un cadre de travail où l’individu fait partie d’une équipe. Il fait partie d’une action négociée entre plusieurs partenaires, ce qui n’est pas le cas de l’écrivain. Objectivement, il n’est pas créateur mais co-énonciateur avec un mandant. Cela lui confère tout de même une responsabilité morale dont il ne peut s’échapper. »
À notre sens, cette affirmation est partiellement juste, car un écritexte ne peut être considéré comme un énoncé puisqu’il n’est pas adressé à un moment précis (Benveniste, 1966 et 1974) ; l’espace numérique étant accessible en tout lieu et en tout temps. Toutefois, il ne s’agit pas d’un espace isolé de toute réalité : les écritextes portent des marques énonciatives et contextuelles permettant d’identifier les intentions des organisations en demande de ces productions textuelles. Leur rôle oscille entre délégation totale de la création et co-construction des contenus, créant ainsi une dynamique de collaborativité selon l’idée de Bolter (2021). Cela devrait engendrer des obligations et des droits liés à la reconnaissance de l’autorialité ou de la co-autorialité, incarnée notamment par la signature ou des mentions spécifiques dans les contenus publiés avec pour corollaire la reconnaissance d’un droit moral, comme entendu dans le Code de la Propriété intellectuelle français. C’est pourquoi, le terme « écritexte » a été proposé afin de distinguer ces productions hybrides, qui répondent à des contraintes techniques tout en véhiculant des significations stratégiques. Ce néologisme permet de dépasser les catégories traditionnelles des écrits professionnels et de mieux analyser les enjeux d’éthique et de responsabilité dans un contexte numérique.
Pour résumer, les rédacteurs web possèdent des compétences spécifiques en matière de création de contenus organisationnels, plus particulièrement des écritextes, optimisés pour le référencement (SEO), l’engagement utilisateur et l’accessibilité. Ils portent des valeurs d’honnêteté, d’exactitude et d’équité, fondamentales pour assurer la qualité et la fiabilité des contenus produits. L’évaluation de ces compétences et valeurs repose sur la reconnaissance de leur identicité, concept que nous proposons comme un prolongement spécifique de l’identité numérique telle que définie par Cardon (2021). Si l’identité numérique décrit principalement les traces laissées par les individus en ligne et leur gestion dans des contextes variés, l’identicité met l’accent sur la visibilité et la reconnaissance des contributions spécifiques des rédacteurs web. Elle reflète donc à la fois leur rôle distinctif dans la création de contenus et la manière dont ces contenus s’inscrivent dans un écosystème éditorial particulier. L’identicité et l’autorialité permettent ainsi de valoriser leur contribution unique et traçable à la création de valeur. Ensemble, elles permettent aussi d’assurer une traçabilité des contenus stratégiques, en particulier des écritextes, et une responsabilité éditoriale au sein de cet environnement plus transparent.
b) Les enjeux organisationnels
Les organisations sont souvent aux prises avec des enjeux qui peuvent entrer en conflit avec l’exigence de transparence comme la protection des secrets commerciaux, la gestion des crises de réputation, ou bien encore la stratégie de communication. Ces enjeux sont autant de facteurs qui peuvent créer des tensions. Car, inévitablement, les rédacteurs sont aux prises avec des contraintes variées, comme les exigences des clients, les délais serrés, et les attentes du public. Ils doivent également faire face à de potentiels conflits entre leur devoir de délivrer des informations honnêtes et précises et les demandes de leurs employeurs ou clients qui peuvent parfois chercher à manipuler l’information (Beaudet, Rey, 2014).
L’éthique rédactionnelle ne se limite pas à une simple application de principes moraux, car elle doit naviguer entre les enjeux organisationnels et les exigences de transparence, tout en cherchant à éviter les conflits et à garantir la crédibilité des contenus créés. Ces deux dimensions — transparence et enjeux organisationnels — ne sont pas opposées, mais interagissent dans un équilibre fragile, où les organisations doivent concilier leur besoin de préserver leurs intérêts stratégiques (confidentialité, compétitivité) avec la nécessité d'assurer une traçabilité et une qualité informationnelle suffisantes pour répondre aux attentes des parties prenantes.
Ainsi, l’éthique rédactionnelle vise à instaurer des pratiques concrètes qui permettent d’atténuer les effets du paradoxe de la transparence qui souligne les limites de la régulation actuelle, et ce, tout en clarifiant les processus de création. Pour y parvenir pleinement, elle pourrait s’appuyer sur trois leviers complémentaires qui feront l’objet d’un autre article :
la traçabilité des contributions individuelles par la reconnaissance de l’autorialité des rédacteurs ;
la mise en place de normes de qualité rédactionnelle incluant des critères d’exactitude et de qualité rédactionnelle allant au-delà des exigences SEO dictées par les moteurs de recherche ;
la réduction des effets des bulles de filtre en encourageant la diversité des voix et des perspectives.
***
Les limites des cadres éthiques et réglementaires existants soulignent la nécessité d’envisager des solutions technologiques capables de garantir la transparence et la valorisation des contributions des rédacteurs web. Dans cette perspective, l’intelligence artificielle et la tokenisation apparaissent comme des outils efficients et méritant une exploration approfondie.
L’éthique rédactionnelle au prisme de l’IA et de la tokenisation
Nous avons vu précédemment que l’Artificial Intelligence Act devrait entrer en vigueur en 2025 faisant de l’Europe la pionnière dans la régulation de l’IA. Antoine Raulin (2023) propose une définition assez complète de cet objet :
« La norme ISO de 1995 a défini l’Intelligence artificielle (IA) comme la « capacité d’une unité fonctionnelle à exécuter des fonctions généralement associées à l’intelligence humaine, telles que le raisonnement et l’apprentissage. (…) Si l’on accepte cette définition, les évolutions actuelles invitent à distinguer plusieurs approches :
• les dispositifs embarquant des briques d’IA dites « faibles », qui permettent d’optimiser le traitement de l’information par des TIC avancées, et les dispositifs futurs qui pourraient embarquer des briques d’IA dites « fortes » ;
• les « algorithmes mobilisant de l’apprentissage », qui reposent sur une capacité à s’entrainer et à apprendre sur la base de données optimisée à cet effet, et les « algorithmes sans apprentissage » dont les raisonnements ne dépendent pas des données d’entrée mais de formalismes logiques préalablement codés par les concepteurs. »
Selon cette définition, on comprend bien les avantages associés à cette technologie pour les organisations : automatisation des tâches et analyse rapide de grandes quantités de données pour gagner en efficacité et agilité (détection de fraudes dans les secteurs tels que la finance ou l’analyse de données médicales, entre autres exemples). Cela renforcera l’idée que l’IA offre des bénéfices tangibles, malgré les défis qu’elle pose. Bien sûr, cela n’est pas sans risques ; des risques que l’Artificial Intelligence Act classe en quatre niveaux : inacceptables, élevés, limités ou minimaux.
Notre objet d’étude et notre approche optimiste nous amènent à formuler le postulat que cette avancée technologique pourrait être une opportunité de développer un espace numérique plus transparent tout en améliorant les conditions de travail des rédacteurs web visibilisés grâce à une éthique rédactionnelle devenue une norme acceptée de tous. Ce postulat repose sur plusieurs éléments :
1. La visibilité accrue des rédacteurs grâce à l’identicité
L’identicité, entendue comme l’ensemble des traces numériques laissées par les rédacteurs web contribuant à leur reconnaissance professionnelle, joue un rôle central dans leur visibilité. En effet, en attribuant de manière explicite la paternité ou co-paternité des contenus, ces traces numériques pourraient incarner la reconnaissance des rédacteurs en qualité de contributeurs essentiels à la chaîne éditoriale. Concrètement, cela pourrait se formaliser par l’intégration de métadonnées précisant l’auteur dans les contenus et systèmes de gestion des contenus, ou bien encore par la signature systématique des textes.
2. La garantie de traçabilité grâce à l’autorialité
L’autorialité, entendue comme la reconnaissance formelle du statut d’auteur ou de co-auteur d’un contenu, constitue un levier essentiel pour assurer la traçabilité des contenus stratégiques. Dans ce cadre, la tokenisation se présente comme un outil technologique efficace, permettant notamment d’associer chaque écritexte à un token unique enregistré sur une blockchain pour en garantir l’authenticité. C’est donc un outil de choix pour formaliser et gérer les collaborations, notamment dans des environnements de co-création, où les contributions de différentes parties peuvent être enregistrées dans un registre immuable de manière transparente tout comme les transferts de propriété.
3. L’amélioration des conditions de travail
Une reconnaissance institutionnalisée des rédacteurs web, soutenue par des normes d’éthique rédactionnelle, contribuerait à revaloriser ce métier, aujourd’hui fragilisé par l’invisibilisation dont découle une certaine forme de précarité. Cette reconnaissance pourrait ouvrir la voie à des pratiques plus équitables en termes de rémunération et d’attribution des droits.
Ainsi, bien que notre postulat nécessite une validation empirique, il est ancré dans une réflexion théorique et technologique visant à transformer les pratiques rédactionnelles. Cette hypothèse mérite d’être explorée dans la mesure où elle offre des pistes concrètes pour repenser les enjeux de transparence, de traçabilité et de qualité des contenus dans un environnement numérique en constante mutation.
Nonobstant, l’intelligence artificielle en ce domaine ne peut tout. Au cœur de ce nouveau contrat de lecture intervient une autre technologie complémentaire, prisée des cryptomonnaies : la tokenisation.
Une technique-outil au cœur d’un environnement décentralisé
Est-ce pour s’affranchir des défauts du système bancaire traditionnel et se prémunir des crises financières que le bitcoin, premier moyen de paiement natif de l’Internet et international, a été créé ? Nul ne saurait l’affirmer avec certitude. Il en est de même de l’identité de la personne ou groupe de personnes qui a publié le livre blanc, Bitcoin : A Peer-to-Peer Electronic Cash System, sous le pseudonyme de Satoshi Nakamoto en 2008. On y découvre une technologie de stockage et de transmission de données fonctionnant sans organe central de contrôle, c’est-à-dire sans banques centrales, comme la Banque Centrale européenne ou la Banque de France, ni autorités de régulation financière, comme l’Autorité des marchés financiers (AMF) en France : la blockchain. Celle-ci présente l’avantage d’enregistrer toutes les transactions de manière décentralisée et est administrée par un réseau d’ordinateurs (ou nœuds) qui vérifient et valident chaque transaction à l’aide de protocoles de consensus. Ces derniers garantissent ainsi l’intégrité et la sécurité de la blockchain en assurant que toutes les transactions sont conformes aux règles établies. Ce réseau est généralement maintenu par des participants indépendants, appelés mineurs ou validateurs, qui utilisent des protocoles de consensus pour garantir l’intégrité et la sécurité de la blockchain. Dans cet environnement décentralisé, la tokenisation y joue un rôle polysémique, car elle est à la fois une technique et un outil.
La tokenisation consiste à transformer un actif (qu’il soit physique, numérique ou financier) en un jeton numérique (token) sur une blockchain. Cette technique permet de représenter la propriété, l’authenticité ou d’autres attributs d’un actif de manière numérique et traçable. Les tokens peuvent ainsi être utilisés pour représenter divers types d’actifs : biens immobiliers, œuvres d’art, actions, données et tous types de contenus.
Sans la blockchain, le processus de tokenisation ne peut fonctionner. En transformant un écritexte en jeton numérique (token) sur une blockchain, la tokenisation offre bien plus qu’une simple représentation numérique de la propriété intellectuelle. Elle constitue un mécanisme clé pour renforcer l’éthique rédactionnelle, car elle associe à chaque contenu une traçabilité et une authenticité garanties. En enregistrant le token propre à chaque écritexte, la blockchain permettrait ainsi de protéger et garantir des éléments fondamentaux de l’éthique rédactionnelle : la paternité des contenus, leur intégrité et la transparence dans leur usage. « Support de l’authenticité et de la traçabilité » (Mendoza-Caminade, Poujade, 2023), elle protège également les droits des rédacteurs en assurant une transparence totale quant aux modifications de leurs contenus et de leur vente. Dans ce contexte, l’IA peut aider à automatiser et sécuriser la tokenisation, en optimisant la création de contenus et en assurant leur traçabilité.
Rôle de l’IA dans le processus de tokenisation d’un article de blog
Pour illustrer le rôle que pourrait jouer l’IA dans la tokenisation d’un article de blog, pouvant être vendu sous forme de NFT (jetons non fongibles), nous proposons le processus suivant. Ce mécanisme, bien que technique, ne prétend pas résoudre à lui seul les enjeux de reconnaissance des rédacteurs. Toutefois, il contribue à poser les bases d’une éthique rédactionnelle en offrant des garanties de traçabilité, d’attribution, et d’authenticité.
Étape 1 : Création du Contenu
Le rédacteur crée le contenu via une plateforme dédiée ou un système de gestion de contenu (CMS) avec un compte utilisateur spécifique. À ce stade, l’IA peut être mobilisée pour :
vérifier l’authenticité et la qualité du contenu (détection de plagiat, vérification de l’unicité) ;
intégrer automatiquement des métadonnées associées, telles que le nom du rédacteur, la date de création et des informations sur la contribution, favorisant ainsi la reconnaissance explicite des auteurs.
Étape 2 : Tokenisation
Le contenu est tokenisé, c’est-à-dire crypté (une série de chiffres est associée au contenu ou à l’écritexte qui le remplace), en utilisant une plateforme blockchain. Ainsi, chaque contenu reçoit un token unique via un smart contract (programmes qui s’exécutent automatiquement lorsque certaines conditions sont remplies) qui automatise l’attribution et la gestion des droits : ce token non fongible (NFTs - Non-Fungible Tokens), créé selon les normes RC-721 et ERC-1155 sur Ethereum, représente la propriété, l’authenticité et les droits associés au contenu..
Lorsqu’un contenu est tokenisé, il est associé à une clé privée et une clé publique :
– la clef privée est utilisée pour prouver la propriété du token ; elle ne doit jamais être partagée, car elle permet de contrôler le token.
– la clé publique est utilisée pour identifier le token et peut être partagée sans risque.
En cas de partage de la clé de tokenisation en co-autorialité, la solution la plus sécurisée serait de créer des tokens multi-signatures (multi-sig), où plusieurs clés privées sont nécessaires pour autoriser une modification du contenu. Cela permettrait à l’entreprise et au rédacteur de valider conjointement les modifications ou les transferts du token. Quant à la clé publique, qui identifie le token, elle peut être partagée sans risque avec l’organisation. La co-autorialité du contenu est prouvée, et ce, sans compromettre la sécurité du token. Puis, le contenu est stocké de manière décentralisée (par exemple, via IPFS). Le contenu peut aussi être placé dans une ontologie appropriée pour faciliter sa recherche et son utilisation. Un lien vers ce dernier est inclus dans les métadonnées du token qui incluent l’auteur, la date de création, un résumé du contenu. En intégrant ces étapes, la tokenisation favorise une visibilité accrue des contributions, rendant impossible l’appropriation anonyme ou injustifiée des contenus
Exemple de Contrat Intelligent (Smart Contract) pour la Tokenisation de contenus
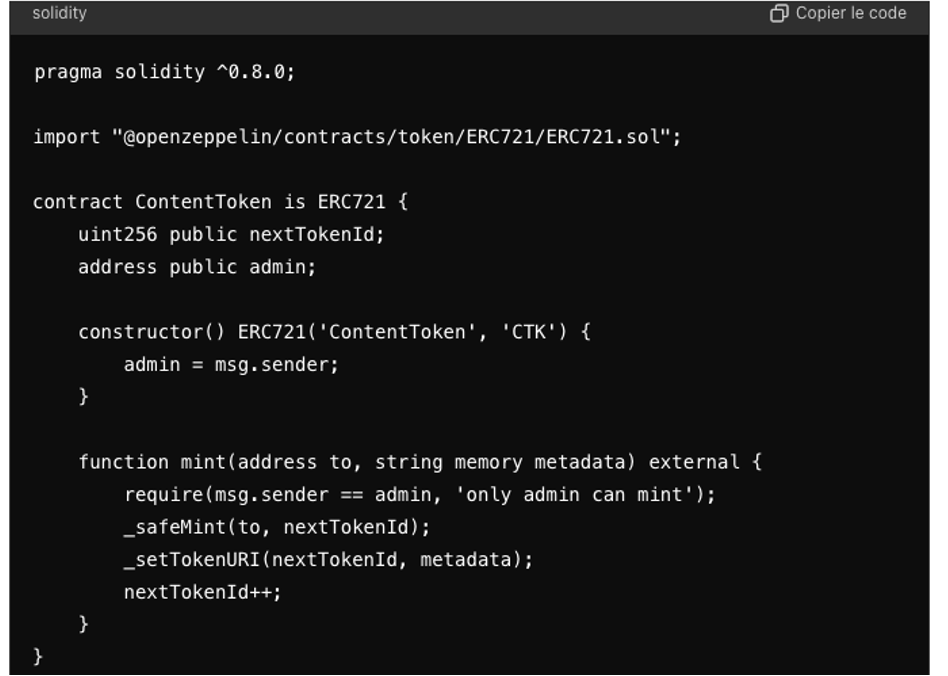
Ce code Solidity, utilisant le standard ERC-721, définit un smart contrat permettant de créer des tokens non fongibles (NFTs) appelés « ContentToken ».
Étape 3 : Publication
La publication peut être réalisée sur le site de l’organisation : le CMS de l’entreprise (WordPress, Drupal, par exemple) est configuré pour intégrer des plugins ou des API spécifiques pour interagir avec la blockchain, récupérer les données du token (par exemple, Alchemy, Infura pour Ethereum) et afficher le contenu associé. Pour la publication sur un site web autre que celui de l’entreprise, le plugin vérifie le token sur Ethereum. Le contenu est alors affiché avec une mention « Tokenized by [Author] » et un lien vers la blockchain pour vérifier l’authenticité. Le contenu est ensuite affiché sur le site web avec les informations de l’auteur, prouvant ainsi la paternité grâce au token. En intégrant des principes éthiques (reconnaissance, responsabilité, authenticité), ce processus va au-delà d’une simple solution technique.
Étape 4 : Gestion des droits et des transactions
Les smart contracts peuvent être configurés pour inclure des mécanismes de vente en une fois ou abonnement avec partage des revenus ou non des revenus en cas de co-autorialité. Quant aux transactions, elles sont enregistrées de manière immuable sur la blockchain, assurant transparence et sécurité.
À ce niveau, des outils utilisant l’intelligence artificielle peuvent être mobilisés pour analyser les données associées aux tokens, telles que les métadonnées, les interactions ou les transactions sur la blockchain. Ils permettent de mieux comprendre l’usage des contenus tokenisés, d’évaluer leur impact en termes de diffusion ou d’engagement, et de fournir des informations détaillées pour une gestion optimisée. Quant aux utilisateurs, ils peuvent gérer leurs tokens via des portefeuilles numériques comme MetaMask, sur des plateformes comme OpenSea, Rarible, ou d’autres solutions personnalisées permettant d’acheter, vendre ou échanger les tokens.
La tokenisation arrimée à l’IA se présente donc comme une solution pour renforcer l’éthique rédactionnelle en garantissant la paternité et la protection des rédacteurs web. Dans la cadre de la co-autorialité, elle offre également aux organisations la possibilité de monétiser leur portefeuille de tokens et de les valoriser : ils deviennent de véritables actifs identifiables dans le bilan comptable. Cela est d’autant plus vrai si les organisations créent des ontologies par secteur d’activité, ce qui permettrait également de développer une véritable politique de knowledge management et ainsi conserver précieusement leur mémoire et leurs pratiques.
Les limites de l’approche
Bien que cette avancée technologique ouvre des perspectives prometteuses pour voir l’émergence d’une éthique rédactionnelle, elle soulève aussi des interrogations sur sa mise en œuvre effective. Nos hypothèses nécessitent une validation empirique pour évaluer leur faisabilité et leur impact concret sur les conditions de travail des rédacteurs et la qualité des contenus produits.
Par ailleurs, l’introduction des principes clés de l’éthique rédactionnelle n’est pas exempte de biais potentiels pouvant se manifester à différents niveaux :
1. Biais technique
Les infrastructures nécessaires pour implémenter ces outils, telles que les systèmes de tokenisation, sont souvent centralisées ou contrôlées par un petit nombre d’acteurs technologiques. Cela pourrait accentuer les déséquilibres de pouvoir au détriment des rédacteurs, en leur imposant des contraintes supplémentaires ou des dépendances techniques.
2. Biais organisationnel
Les organisations pourraient détourner ces mécanismes pour renforcer leur propre contrôle sur les contenus, par exemple en s’attribuant les droits d’autorialité plutôt qu’aux rédacteurs eux-mêmes, perpétuant ainsi leur invisibilisation.
3. Biais économique
L’accès aux technologies nécessaires pour garantir l’identicité et l’autorialité (comme la tokenisation) pourrait être inégal, favorisant les grandes organisations aux dépens des rédacteurs indépendants ou des petites structures.
Si la tokenisation arrimée à l’IA est donc une piste à explorer pour favoriser l’éthique rédactionnelle, son usage mérite un encadrement spécifique. La vente en 2022 d’un tweet de Jack Dorsey, fondateur de Twitter, pour 2,9 millions de dollars soulève aussi des questions sur la spéculation dans le marché des NFTs avec en filigrane la marchandisation excessive des contenus qui, en d’autres temps, auraient été considérés gratuits et accessibles à tous. Car, l’approche favorise aussi la transformation des œuvres numériques en objets de spéculation plutôt que d’encourager leur partage ou leur libre accès avec pour corollaire une dynamique de marché privilégiant les profits au détriment de l’intérêt public ; voire un accès restreint aux informations de qualité aux seuls utilisateurs disposant des moyens financiers pour y accéder en cas de monétisation systématique des contenus.
De plus, la co-autorialité, si elle n’est pas répartie de façon équitable, peut dans le cadre de la tokenisation être source conflits quant à la part de la propriété de chacun. Cela est d’autant plus vrai si les systèmes multi-signatures sont utilisés pour la validation de modifications.
Par ailleurs, la tokenisation n’est pas si simple à mettre en œuvre. D’une part, elle a des impacts environnementaux : consommation énergétique, empreinte carbone et les déchets électroniques. Il est cependant possible de surmonter ces obstacles à adoptant plusieurs solutions comme l’usage d’algorithmes de consensus plus écologiques, le développement de programmes de recyclage et de réutilisation des composantes électroniques, etc. En ce sens, la blockchain Algorand qui utilise un mécanisme de consensus dit « carbon-negative » peut être une piste sérieuse. D’autre part, elle peut être difficilement adoptée par certains moteurs en raison du possible conflit de normes que cela créerait du fait de l’utilisation de l’IA pour générer du contenu automatique, voire de faux contenus à des fins malveillantes, vendus en tant que NFTs. On voit bien là toute la difficulté pour distinguer les œuvres authentiques des œuvres automatisées.
En commençant cet article, nous avons abordé la notion d’écritexte. Ce concept a permis de souligner la complexité des contenus textuels numériques qui oscilllent entre matérialité et intangibilité. Ce constat nous a conduit à explorer la dynamique de production des écritextes en mettant en lumière les enjeux cruciaux posés par l’exigence de transparence en terrain numérique. Pour y parvenir, notre approche holistique, distincte des approches existantes qui se concentrent principalement sur les normes de régulation et les principes moraux, a exploré la convergence entre les outils technologiques émergents et les enjeux éthiques. Ainsi, nous avons tenté de démontrer que, malgré les points de tension, il est possible de promouvoir une éthique rédactionnelle au sein des organisations au regard de la nécessaire reconnaissance de l’identicité et l’autorialité des rédacteurs web. Cette reconnaissance, essentielle pour valoriser leurs compétences, permettrait aussi de répondre aux exigences croissantes en matière de fiabilité des informations en ligne grâce à la tokenisation et l’IA. Ainsi, en contribuant à l’émergence d’un environnement numérique plus éthique, où les contenus sont non seulement vérifiables, mais également respectueux des contributions de leurs créateurs, ces techniques-outils offrent des perspectives prometteuses pour répondre à ces défis.
Cependant, leur mise en œuvre nécessite une vigilance accrue face aux risques de biais techniques, organisationnels et économiques. Ces biais, s’ils ne sont pas anticipés, pourraient limiter l’accès des rédacteurs indépendants aux outils nécessaires, ou renforcer les déséquilibres de pouvoir entre les grandes plateformes technologiques et les créateurs individuels. Ces technologies soulèvent aussi une question essentielle : comment instaurer un équilibre entre innovation technologique énergivore et principes éthiques dans un écosystème numérique en constante mutation ? Par ailleurs, si l’émergence d’une éthique rédactionnelle numérique est non seulement souhaitable, mais aussi réalisable, elle nécessite un engagement collectif des acteurs de l’écosystème numérique, allant des plateformes technologiques aux organisations, afin d’instaurer des pratiques transparentes et responsables. En effet, l'IA peut aussi induire une mauvaise praxis rédactionnelle non négligeable si elle est guidée par une déontologie déficiente. Le processus de tokenisation arrimée à l'IA justifie donc une exploration sérieuse, mais aussi précautions et contrôles pour préserver un écosystème informationnel plus transparent et fiable.
Ce chantier reste ouvert et appelle à des études empiriques pour évaluer l’impact concret de ces solutions sur les rédacteurs web, les organisations, et les utilisateurs finaux.
BIBLIOGRAPHIE
Badouard, R. (2020). La régulation des contenus sur Internet à l’heure des « fake news » et des discours de haine. Communications, 106, 161-173.
Barthes, R. (1967). La mort de l’auteur. Manteia.
Beaudet, C., et Clerc, I. (2008). L’enseignement de la rédaction professionnelle au Québec. Quels fondements disciplinaires ? Quelle reconnaissance institutionnelle ?. Actes de la conférence internationale De la France au Québec : l’écriture dans tous ses états . https://inspe.univ-poitiers.fr/wp-content/uploads/sites/513/2020/05/BeaudetClercCONF.PDF
Beaudet, C., et Rey, V. (2014). Éthique appliquée et communication écrite : qu’en disent les rédacteurs professionnels ? Revue internationale de communication sociale et publique, n°11, 29-44.
Benveniste É. (1966). Problèmes de linguistique générale, tome 1. Paris : Gallimard, 1966.
Benveniste É. (1974). Problèmes de linguistique générale, tome 2. Paris : Gallimard, 1974.
Bolter J. David (2001). "Writing Space: Computers, Hypertext, and the Remediation of Print" Lawrence Erlbaum Associates.
Broudoux E. (2022). Éditorialisation et autorité, Deboeck Supérieur.
Canivet I. (2021). Bien rédiger pour le Web. Stratégie de contenu pour améliorer son référencement naturel, 5e édition, Eyrolles, 2021.
Cardon D. (2019). Culture numérique. Presses de Sciences Po.
Chartron, G., & Raulin, A. (2022). L’intelligence artificielle et ses impacts sur les dispositifs numériques de gouvernance. I2D - Information, Données & Documents, 59(1), 5-12.
Chatry S. (2015). La protection des œuvres publicitaires par le droit d’auteur en France. hal01301179. https://hal.science/hal-01301179/document
Citton, Y., Lechner, M., & Masure, A. (éds.). (2023). Angles morts du numérique ubiquitaire (1‑). Presses universitaires de Paris Nanterre. https://doi.org/10.4000/11tv9
Comité technique ISO/IEC JTC 1 (2015). Norme ISO/IEC 2382-28 (1995). https://www.iso.org/obp/ui/fr/#iso:std:iso-iec:2382:-28:ed-1:v1:fr
Dalbin, S., et Guyot, B. (2007). Documents en action dans une organisation : des négociations à plusieurs niveaux. Études de communication, 30, 55-70.
De Angelis, R., (2022). Lire, écrire, co-écrire, partager, référencer les écrits. Transitions linguistiques au sein de la culture numérique. Actes du congrès de l’Association Française de Sémiotique (2022). https://doi.org/10.25965/as.8608
Doueihi, M. (2008). La grande conversion numérique, Seuil.
Fonvielle, S., Pereira, M.E., Rey, V., et Roubaud M.N. (2012). Du rédigeur au rédacteur : vers une définition de l’écriture professionnelle. Actes du Colloque Stratégies d’écriture, stratégies d’apprentissages de la maternelle à l’université.
Foucault M. (1969). Qu’est-ce qu’un auteur ? Bulletin de la Société française de philosophie, 63 (3), 73-104.
Fraenkel B. (2006). Actes écrits, actes oraux : la performativité à l’épreuve de l’écriture. Études de communication, 29, 69-93.
Gallot, S., & Verlaet, L. (2016). La transparence : l’utopie du numérique ?. Communication & Organisation, 49, 203-217.
https://doi.org/10.4000/communicationorganisation.5277
Genette, G. (1987). Seuils, Editions du Seuil.
Gervais, D. (1998). La notion d’œuvre dans la Convention de Berne et en droit comparé. Librairie Droz, 9.
Goffman, E. (1973). La Présentation de soi. La Mise en scène de la vie quotidienne I. Editions de minuit.
Jeanneret, Y. (2001). Critique de la notion de transparence dans les pratiques informationnelles. Dans Glossaire critique de la société de l’information. UNESCO.
Krinsky, J., Simonet, M. (2012). Déni de travail : l’invisibilisation du travail aujourd’hui. Sociétés contemporaines, 87, 5-23. https://doi.org/10.3917/soco.087.0005
Kuhn, Th. (1962). La structure des révolutions scientifiques. Flammarion, 1970.
Labasse, B. (2009). L’écrit professionnel : ambiguïtés et identités d’un objet académique. Pratiques (143-144).
Lamri, J., Tertrais, G. et Silver, A. (2023) . Chapitre 1. Comprendre les IA génératives et leur portée. Travailler à l'ère des IA génératives. ( p. 23 -67 ). EMS Éditions.
Lefebvre-Reghay, S. (2024). Le nouveau paradigme du contenu textuel dans les organisations : une analyse multidimensionnelle dans le paysage numérique. Actes de la Document Academy, 10.
Mendoza-Caminade, A., Poujade H. (Dir.). (2023). NFT et Droits. Presses de l’Université Toulouse Capitole. ⟨10.4000/11sp5⟩. ⟨hal-04610472⟩
Mayeur, I., Desprès-Lonnet. M. (2020). Aux origines du textiel. Entretien avec Marie Després-Lonnet , Corela. DOI : https://doi.org/10.4000/corela.11756
Nakamoto S., 2008, Bitcoin : un système de paiement électronique pair-à-pair. https://bitcoin.org/files/bitcoin-paper/bitcoin_fr.pdf
Pariser, E., (2012). The Filter Bubble : What The Internet Is Hiding From You, Editions Penguin, New-York.
Raulin, A. (2023). L’intelligence artificielle dans la gestion et la valorisation de l’information : clés de repérage (histoire et analyse). Dans « L’intelligence artificielle » I2D — Information, données & documents.
Simon, H. A. (1969). The Sciences of the Artificial. MIT Press.
Souchier E. (1996), L'écrit d'écran, pratiques d'écriture & informatique. Communication et langages, 107, no 1, 105–119.
 Contacter l'auteur
Contacter l'auteur
 Tous les articles
Tous les articles